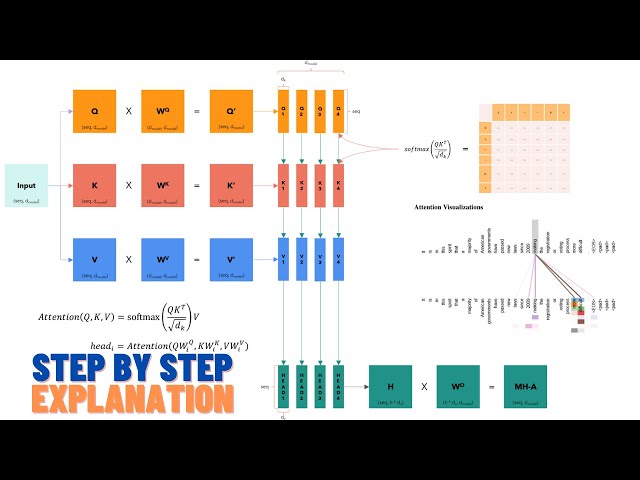
Cross-attention is a way to merge two token or embedding sequences in transformer architecture.
- POST: https://vaclavkosar.com/ml/cross-attention-in-transformer-architecture
- Self-attention: https://vaclavkosar.com/ml/transformers-self-attention-mechanism-simplified
- Feed-forward layer: https://vaclavkosar.com/ml/Feed-Forward-Self-Attendion-Key-Value-Memory
Cross-attention is a very similar to self-attention, except we are putting together two sequences asymmetrically. One of the sequences serves as a query, while the other as a key and value.
an attention mechanism in Transformer architecture that mixes two different embedding sequences
the two sequences can be of different modalities (e.g. text, image, sound)
one of the modalities defines the output dimensions and length by playing a role of a query
similar to the feed forward layer where the other sequence is static





4 Comments